


Every business system processes entropy somehow — by product managers who formalize ambiguous workflows, by account managers who fill in endless CRM fields, in the free-text notes nobody reads. Agentic capabilities give you five new places to put that work: software engineering, user interface, data ingestion, run-time decisions, and graph or vector storage. Where you put that work will shape your cost structure, your risk posture, and your users’ frustration for years.
Thanks for reading Prosaic Times — share the entropy with a friend!
1. Every computer system we build is an imperfect representation of reality
“No, I didn’t go to Catholic school. Why do you ask?”
An eminent partner at a previous consultancy looked at me across an empty conference room and explained: “You have an instinct for mapping data onto a grid -- you have a Cartesian mindset, which many good consultants learn from a Jesuit education.”
Grids distort as much as they reveal. We’ve all seen (or built) grids for evaluating outsourcing vendors: 20 points for stability, 30 for service quality, 30 for cost, 10 for innovation. These never produce the right answer -- they ignore non-linearity. You won’t select a vendor below your financial stability threshold no matter how cheap; once a bidder clears it, you care about cost and service, not financial stability.
Every slide, every analysis, every system is an imperfect representation of reality. CRM systems are a simplified model of how your business interacts with customers. Operational systems are a simplified model of your factory. I learned this crawling around telecom carriers in the 1990s, where you had to ask the service techs which USOC “1FR” lines had bridge taps that had to be removed before upgrading to DSL.
2. The world is entropic
Do you know whether that deal will close next week and at what price? Whether your flight to Chicago will land on time? Or whether a new employee will turn out to be a hero or a goat? I do not.
As a recovering history major, I believe the past provides counsel on the future. On June 21, 1948, the Small-Scale Experimental Machine became the first computer to run a program stored in its own electronic memory -- 128 bytes of it. Weeks later, Weaver and Shannon published articles foreshadowing many of the problems we struggle with today: automating Byzantine business processes, capturing latent or ambiguous data.
Shannon defined entropy as average amount of uncertainty in a probability distribution. [1] Maybe that’s okay -- in a world without entropy no business could exceed the risk-free rate of return. The more entropic a domain, the more information required, and the more expensive the computer system to automate it.
Weaver laid out a relationship between complexity and uncertainty. Some problems are simple: hold all variables constant except the dependent and independent ones, and you get the steam engine, the automobile, the telephone. A payroll system is the modern analogue -- fixed variables, describable rules, few feedback loops.
Starting in the late nineteenth century, scientists attacked problems of disorganized complexity. Statistics could predict the frequency of calls in a telephone exchange or the claims paid by a life insurance company, even when individual causes remained opaque -- provided each data point was atomic. Fair Isaac developed the FICO score on this basis in the late 1950s.
Then Weaver addressed problems of organized complexity -- macroeconomic management, ecology -- where many inter-related factors multiply uncertainty because each may influence the others in non-obvious ways. Neither nineteenth-century analytics nor twentieth-century statistics could handle them. He hoped new computing devices might, and pointed to the operations research developed in the Battle of the Atlantic as a way forward.
Problems of organized complexity abound in modern business -- order-to-cash, pharmaceutical manufacturing. Given enough contracts, even payroll can turn into one. [2] How much time do knowledge workers spend massaging data into or out of enterprise systems because the system couldn’t capture every exception the domain implied?
We should forgive Weaver for not foreseeing the organized complexity required to address organized complexity -- ERP programs suffer their own, and enterprise technology functions suffer from it themselves.
Writing with Shannon, Weaver named another contributor: latent meaning. Ask an account executive the status of a potential sale and she might say “We’re in final price negotiations with the CHRO and he would like to get a deal signed within the month, but the general counsel is hacked off about a couple of legal terms we require and the CHRO heard he is going to call the CEO and ask that they reopen discussions with another bidder.” What is she supposed to select among the four CRM choices for “status” -- RFP open, RFP submitted, financial negotiations or closed?
Weaver and Shannon identified one more problem -- whether a system creates the desired behavior in the people who interact with it. Think about computer systems the way the military thinks about weapons systems: as inclusive of both the technology and the user. Design choices affect user behavior in unpredictable ways. Complicated interfaces cause users to resist entering data, or to prejudice what they enter to make themselves look good.
Calendaring is deceptively entropic. If Suzy, my assistant, asks me about a conflict at 10 am on a Tuesday, I might say: “I’ll go to the meeting with client 1, because I think that colleague A can cover me in the meeting at client 2. And don’t decline or mark me tentative for anything, because I don’t want anyone giving away the time slot because I might not be there.” I don’t verbalize dozens of assessments about people and situations that shape my decisions. You have entropic communication about organized complexity, latent information and adaptive behavior all in a couple of sentences!
3. Entropy creates cost and frustration when we build systems to represent it
How much time do we all spend in conference rooms debating how much granularity the data model should have -- and how we balance fidelity to the business process versus the cost of maintaining data? How frequently do you find the correct state for a transaction not in the fields designed to contain it, but in the free-text notes or the accompanying email? And how much user anger derives either from the endless fields (specified to capture the subtleties of state) or the disconnect between what the system says and the reality they observe?
Put another way: how much time do we devote to designing around entropy when we build systems? And how much frustration do we create because of the choices we make in doing so?
Operational systems work best when the world can be reduced to stable categories, deterministic workflows, and enumerable exceptions -- all these make a domain easy to formalize. Nobody complains much about most payroll systems because they apply a bounded number of explicit rules to available data.
Analytic systems work best with huge sample sizes and a few relevant independent variables -- making the entropy here tractable to statistical analysis. Machine learning systems for pricing consumer products work because massive amounts of structured data allow probabilistic inference where humans might have struggled to discern patterns.
Other domains and use cases have more intractable entropy. Systems to support treasury management for large enterprises? Modeling a thousand-page contract, involving hundreds of legal entities, dozens of jurisdictions and a thousand different exceptions you can have for a transaction -- all of which generate entropy. Which messiness must you model and which can you simplify away? CIOs have exceeded budget, blown deadlines and angered users in seeking to answer that question.
Yes, machine learning has blunted the impact of entropy in some cases by sniffing out the relationships among variables, but often the sample size is too small and the data too messy for traditional machine learning to be effective. Years ago, someone said collections managers could offer definitive recommendations about how to reduce losses -- why couldn’t CISOs do the same when talking about how to protect the business against cyberattack?
I tried to explain that each demographic segment included millions of households. You could experiment with a new script and quickly determine whether it increased or decreased promises-to-pay. Any large company’s technology environment is a snowflake -- even two companies of similar size and in the same sector may have radically different technology environments. Vulnerability depends not on individual decisions, but on how you connect all the pieces in your environment. And you might not know whether you had been breached for years, if ever. [3]
4. GenAI-based agentic systems process entropy
Deterministic systems cannot process entropy. They can rely on humans to pre-process it for them -- as happens when product managers and engineers sit in a conference room debating how to capture the data required to automate an ambiguous process. They push it on to users like account managers who must fill in endless fields about their pipeline -- and still wonder which option they should select to describe deal status. Or they can store it inertly, like the free-text notes that exist in some customer service platforms. All of these imply some combination of low efficiency and lower effectiveness.
When large language models process text, they convert tokens into vectors, points in a high-dimensional space. This encodes meaning through proximity -- similar meanings cluster together. Large language models can do things deterministic systems cannot do or do poorly:
Allow inference across stored entropy: Written and spoken language are entropic. Vector embeddings allow LLM-based systems to query and analyze free-text notes, email threads and meeting transcripts.
Identify implicit relationships: Vector geometry represents connections between concepts, such as the general counsel wanting to block the deal for group health insurance because he disliked the contract terms.
Understand gradations rather than discrete states: A deterministic system requires the account executive to choose whether the deal has advanced to final negotiations or not. A vector representation of the same situation can sit between two states.
GenAI-based agentic [4] systems give us new ways to process entropy.
At design time, by using software engineering agents to create business logic that reflects all the organized complexity that Weaver described.
As part of the user interface, to mediate between the entropy of written language and a deterministic system, rather than forcing the user to do the work.
Via data ingestion, to derive insights from the massive stores of entropic, unstructured data every enterprise has sitting on its servers.
At run-time (either with or without a human in the loop), to make decisions and execute transactions non-deterministically.
We can also store data used and produced by agentic systems in different ways. Traditional relational databases excel at storing and retrieving massive amounts of transactional data at speed and with near-perfect reliability. They struggle with more ambiguous data, with dense relationships among all the elements. [5] We can choose to store this data either in vector databases or in knowledge graphs.
5. You have choices about how and where you use agents to process entropy
So much of the agentic discourse we see mirrors the flat Cartesian mindset captured in the grid used to evaluate bidders for outsourcing deals. Agents are risky! Or: everything will be an agent!
But entropy is, well, entropic. It varies in scale and shape from business domain to business domain. Sometimes it takes the form of a dense web of interconnections among idiosyncratic products, contracts, processes or customer relationships. Sometimes it takes the form of latent data that doesn’t fit into any data structure you might define. Not a few business domains suffer from multiple forms of entropy.
GenAI-based agents also have disadvantages compared to deterministic systems. GPU-based inferencing is slower and more expensive than CPU-based processing -- a single agentic transaction often costs cents and adds hundreds of milliseconds, where the equivalent deterministic transaction costs fractions of a cent and resolves in single-digit milliseconds. Non-deterministic systems are only as good as the context they receive. An agentic system can process the free-text notes in a CRM platform. It won’t know anything about the discussion two account executives had in the car on the drive back from the customer site. [6]
Abjure the false binaries -- you have real choices about how and where in the value chain you process entropy.
Agentic software engineering: This will be relevant for almost any systems effort. It will allow you to automate all the business logic required to reflect organized complexity with more speed and reliability and less cost. And after agents help you develop the code, you can still apply all the quality assurance mechanisms you have developed over decades, just as you would code developed by hand.
User interface: Retain traditional interfaces for situations where users have to enter small volumes of easily understood data. Develop agentic- or chat-based interfaces for order entry, CRM, or transaction processing systems where users complain about having to fill in screen after screen of data. You can always use a combination of deterministic rules and user validation to ensure the agent correctly captures user intent.
Data ingestion: This is one of the most powerful and most underestimated capabilities. All companies receive and store vast amounts of valuable but entropic data -- eighty percent of corporate data is unstructured and even structured data can be fragmented and hard to correlate. Customer requests for quotation? Customer service notes? Legal contracts. Agentic capabilities can ingest all of this either to support operational processing or to generate new business insights, even if many companies have not focused here yet. [7]
Run-time: This is complicated and has the highest stakes. Use agentic patterns for low-volume heterogeneous decisions. I am helping technology organizations use agents to compare project designs with technology standards. The agent will compare two artifacts (a project design and a standards document) that describe organized complexity in natural language (which is inherently entropic) and determine whether one conforms to the other. Hybrid patterns will probably become increasingly common, with deterministic cores and agents to handle edge cases.
Data storage: Naturally, relational databases will continue to store structured and transactional information. Knowledge graphs excel in modeling product portfolios, customer relationships, process maps and other domains where relationship structure carries meaning. Vector search enables retrieval by meaning from notes, documents and transcripts.
6. Precision matters because entropy is, well, entropic
I have always hated the formulation “The technology is easy. The governance is hard. The organization is hard. The line at the cafeteria is hard.” Here, design choices will shape cost structure, risk posture and user experience for years.
With a capability to process entropy at scale, you have to think about where the entropy sits in your business system -- even a simple one.
Managing invites for the Technology Leadership Forum is lower-entropy than a hundred-million-dollar group insurance deal, but there is plenty of “Joe really wants to attend, but can’t, depending on when a personal conflict lands -- and wants to know if Sally can possibly attend in her place.” I put invitees and members into a knowledge graph and built Agent Serena to translate the entropy in my email into the organized complexity of that graph. [8]
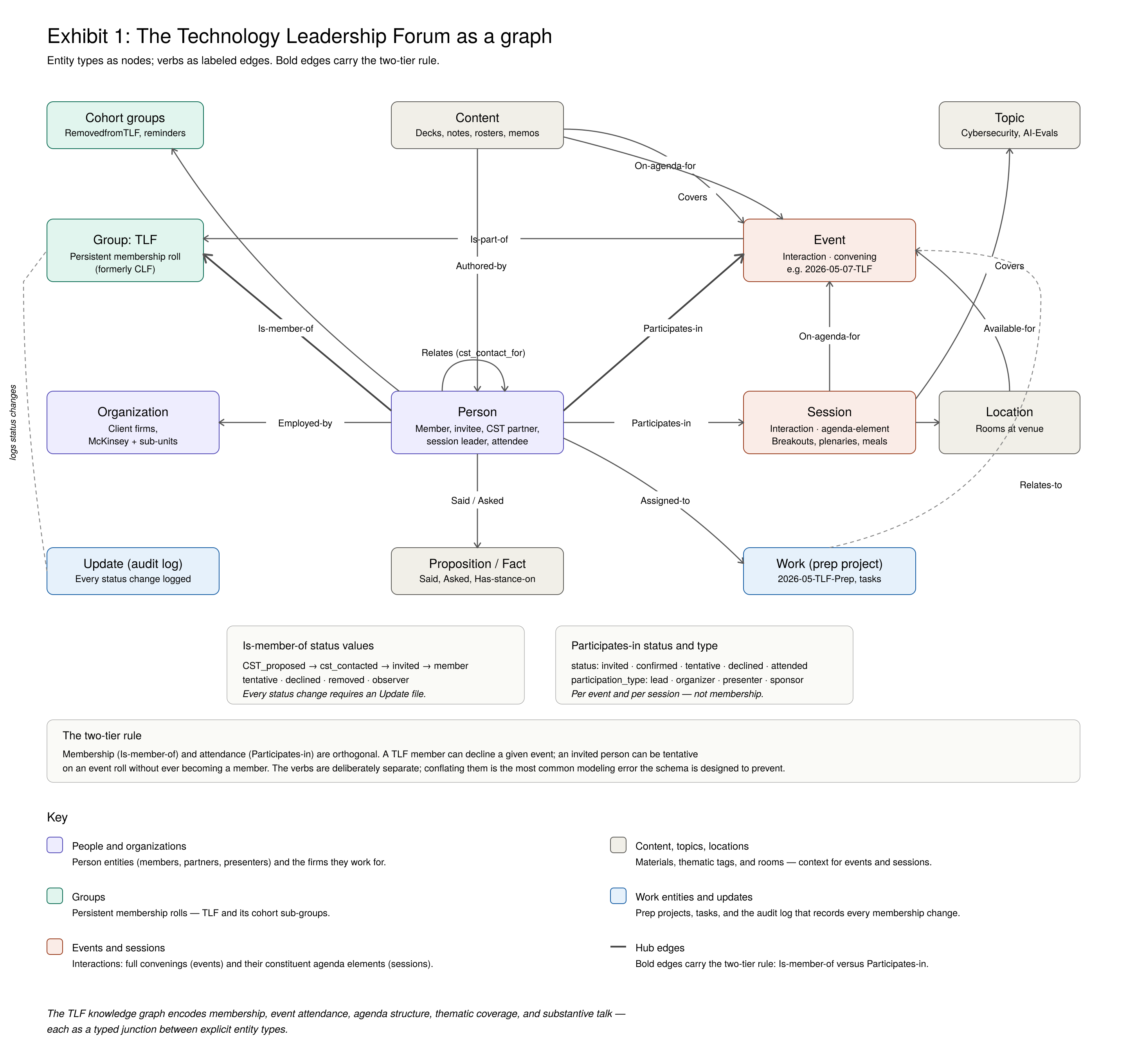
Taking a more highly-scaled domain: entropy pervades enterprise change management in banking. Dozens of interconnected process steps and artifacts; latent information about why a milestone might be at risk of slipping and under what circumstances. Traditionally, banks managed it with managerial talent copying data among word processing, spreadsheet and presentation files. And many, many emails. The result: frustration, expense, and less insight into major programs than anyone would like.
Banks can use agentic software engineering to build a system whose agents ingest program documents, extract the relevant risks, issues, decisions and action items, and store them in a knowledge graph with the relationships among them. Which risks affect which business lines? Which work-stream lead owns which decision? Further agents interrogate emails and videoconference transcripts to enrich the graph. Vector descriptions let program managers search by meaning, not keywords. Still more agents read the graph to assess risks and surface opportunities to improve the program.
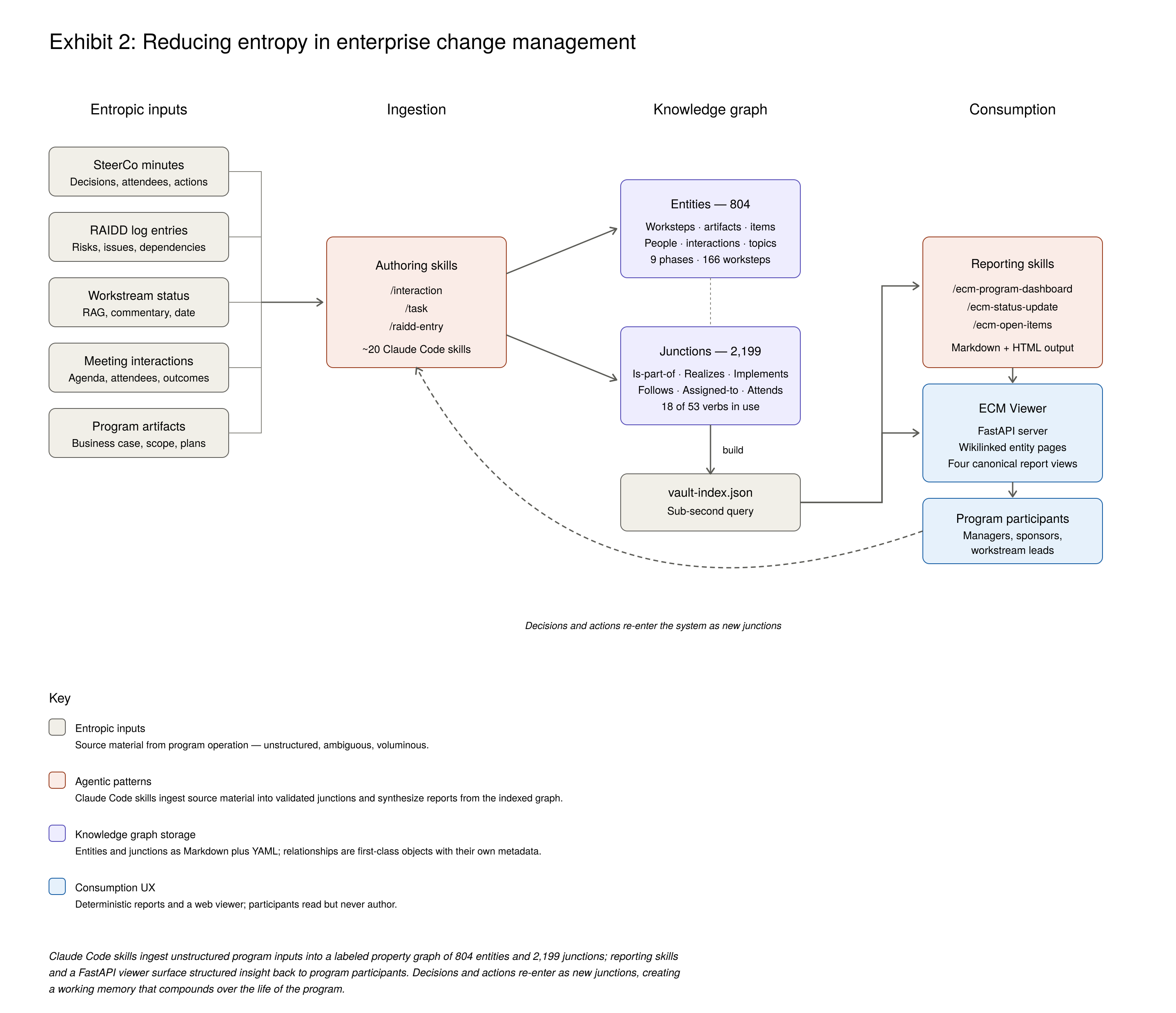
This combination -- agents, knowledge graph, vector database -- removes the entropy from a painful business process. It reduces cost and improves transparency. Those of us on team cyborg (rather than team android) will note that it also empowers managers: less toil, better information.
Agentic systems -- with knowledge graphs and vector databases -- can be transformative. When I wrote that global business must move beyond organized factories and chaotic offices, this is what I meant. The benefits are both economic and humanistic. Nobody grew up hoping to spend days pasting data from email to spreadsheets and back.
Precision matters here. Agents are not magic. Inferencing is expensive, latency is real, and new vulnerabilities arrive faster than we can grasp them. But the harder discipline is the one Weaver and Shannon left us: see your business as a system, find where the entropy sits, and choose where to process it. A flat, Cartesian grid won’t help.
Thanks for reading Prosaic Times — subscribe to receive every issue!
Footnotes
[1] This differs from standard deviation, which measures the magnitude of the spread around a mean. Shannon entropy measures the unpredictability of a distribution. Relevant to us: you can measure the Shannon entropy over a set of non-quantitative values just as you can over a set of quantitative ones. In addition, there are more and less expansive definitions of entropy. I am using a relatively expansive one here.
[2] CityTime is a great example of Kolmogorov complexity. The shortest possible description of the rules governing what every city employee gets paid is approximately as long as the rules themselves — decades of negotiated union contracts, grandfathered provisions, and exceptions to exceptions, each one load-bearing. You cannot compress it further without losing something that will eventually matter. Automation doesn’t reduce this complexity; it just moves it from humans who held it in their heads to engineers who must encode it in systems.
[3] My interlocutor said I was over-complicating the situation and CISOs were probably just incompetent. Sigh.
[4] Agents predate widespread adoption of large language models and genAI. By some definitions, the cruise control system in your car is an agent. You set a speed. It monitors the speed, accelerating when the car drops below that speed (because you are going up a hill) and easing off the throttle when you exceed it. Of course calling LLMs makes agents infinitely more capable than the cruise control in your car.
[5] The notion that relational databases might struggle with relationships among data elements might puzzle some. But only those who have never stared at a screen in the early morning trying to make sense of an outer join -- or who developed a better command of SQL than I ever had.
[6] I like the idea of decision traces and context graphs, but we should be realistic about which decision traces we can capture and which we cannot, unless we want to build a panopticon for ourselves.
[7] I stared in disbelief the first time Zubin Ghafari showed me how he used GenAI to integrate messy CMDB data with other telemetry information. I had assumed this would have taken him weeks.
[8] The natural language front end to Prosaic Graff was a life-saver, but the latency sometimes made me want to put my fist through the screen. So I created Python scripts I could run (instantly) from the Terminal that told me how many members planned to attend or the status of any individual member.

