
Turning relationships into files to vanquish the Chaos Muppets
It’s Gonzo’s company -- we just work here? Maybe a different pattern for modeling relationships between ambiguous data sets can change that.

Thank you to all Prosaic Times readers for helping us break into the double double thousands: two thousand+ subscribers each on Substack and via the LinkedIn newsletter after only four months!

The main argument: Turning relationships into files to vanquish the Chaos Muppets
What you need to know
Chaos Muppets run the corporate world, leaving the rest of us mired in ambiguous, poorly structured data.
That degrades our ability to analyze and automate business domains—we have organized factories and chaotic offices, in part, for this reason.
We need a lightweight, file-native, closed-world semantic system that treats relationships as first-class, schema-validated objects.
Modeling relationships as subject–verb–object junctions—stored as files, constrained by rules, and queried by agents—offers a practical path forward.
In turn, this pattern could improve domains like RFP responses, regulatory compliance and enterprise change programs, among many others
Chaos Muppets run the corporate world
Science has made two great advances in understanding how humans tick in the new millennium: positive psychology and Muppet Personality Theory. Positive psychology asks what makes individuals and communities flourish rather than how to treat mental illness and dysfunction.
Muppet Personality Theory divides all of us into Chaos Muppets, who make their way through life in a “swirling maelstrom of food crumbs, small flaming objects and the letter C.” Order Muppets “resent the responsibility of the world weighing on their felt shoulders, but they secretly revel in the knowledge that they keep the show running.” Scooter and Kermit are Order Muppets. Cookie Monster, Gonzo and Dr. Bunsen Honeydew? Chaos Muppets.
Everyone at the office thinks I’m a Chaos Muppet, but an anarchic sense of humor does not make you a Chaos Muppet. [1] Sam the Eagle is an Order Muppet, and he is humorless. Sam is not humorless because he is an Order Muppet, as Jed Bartlet might have pointed out. Just because I find Dr. Teeth hilarious doesn’t mean I’ve joined the Electric Mayhem. [2]
Mrs. Prosaic Times knows better. She knows how much I hate psychic entropy and how much it prevents me from achieving flow state. She knows that I compensate for an inability to impose order on the universe by imposing order on the utility closet. [3]
Sadly for me, Chaos Muppets run corporate America. You think the guy behind the guy behind the guy is Sam the Eagle? No, it’s Gonzo, with assistance from Fozzie Bear. That’s why we have organizations with incomprehensible remits, duplicative initiatives and documents about documents about yet more documents. It’s Gonzo’s world. We just work here. [4]
I’ve tried generations of software (remember Lotus Organizer?) to try to impose order on professional life. None have been able to model the complexity—and by that I mean the incredibly ambiguous data—of business life at any sustainable level of process overhead. [5] [6] So what information technology have I used? Boxes and boxes of 6″ × 10″ notebooks, sometimes with graph paper in them.
Relationships are the important data, and you can store relationships in files
In the past, I’ve noted that corporate life has chaotic offices and orderly factories. If we can model “office” data, we can go a long way toward resolving that discrepancy.
ProsaicGraff attempts to model complex, many-to-many relationships across ambiguous data sets, using three principles: treat nouns as highly abstracted classes, use verbs to describe relationships between nouns, and use agents for validation and queries.
Treat nouns as highly abstracted classes with minimal metadata
I originally used several topical constructs in structuring my data—a folder for the Technology Leadership Forum, different templates for proposals versus engagements versus service line initiatives. Too messy, not scalable, and hard to figure out where to put things.
Eventually I articulated a set of primitives that dominate my professional life: people, institutions, groups (like TLF!), events (like the May 7th TLF session), meetings, projects, places, milestones, documents and topics. I really wanted to track the relationships between instances within a class or across classes:
The May 7th TLF Session will be held at the McKinsey office in Chicago
Jane Schnauggs [7] is a member of TLF
Jane Schnauggs works at AmalgamatedHealthServices
Brown University Medical School is part of Brown University
The meeting we have tomorrow at 9 am will cover agentic security
You can imagine a million more things like this, all of which might be relevant to my (or, with a slightly different twist, your) professional life.
But relationships in corporate life are complex. A CTO might be a member of TLF, or she might be potentially invited by the McKinsey client team, might have been invited, might have accepted the invite, might have declined the invite or might formerly have been a member but left the group when she took another job with a different set of responsibilities.
A McKinsey partner might be part of the client service team supporting AmalgamatedHealthServices—but he might be a “core member,” who spends a lot of time with that institution across many issues, or a thematic member who focuses on one piece of the organization.
A private equity firm might own all of StandardSocks or it might have a majority stake or a minority stake. Distinctions like this matter.
But what mechanism could I use to capture relationships with the precision I wanted without unbearable process overhead? Neither hashtags, nor wikilinks, nor YAML front matter seemed up to the task.
Why can’t relationships be files?
Could I use a verb to model the relationship between two nouns, a subject and direct object? I could. In some cases, I could even include a third noun in the form of an indirect object.
Eventually I built out 33 verbs, organized into eight top-level categories in the vault (employment and affiliation, interpersonal, membership and participation, content, structure, geography, knowledge and a generic catch-all—see Verbs/).
This is for Attends (which describes a relationship with an educational institution):
Verb - Attends
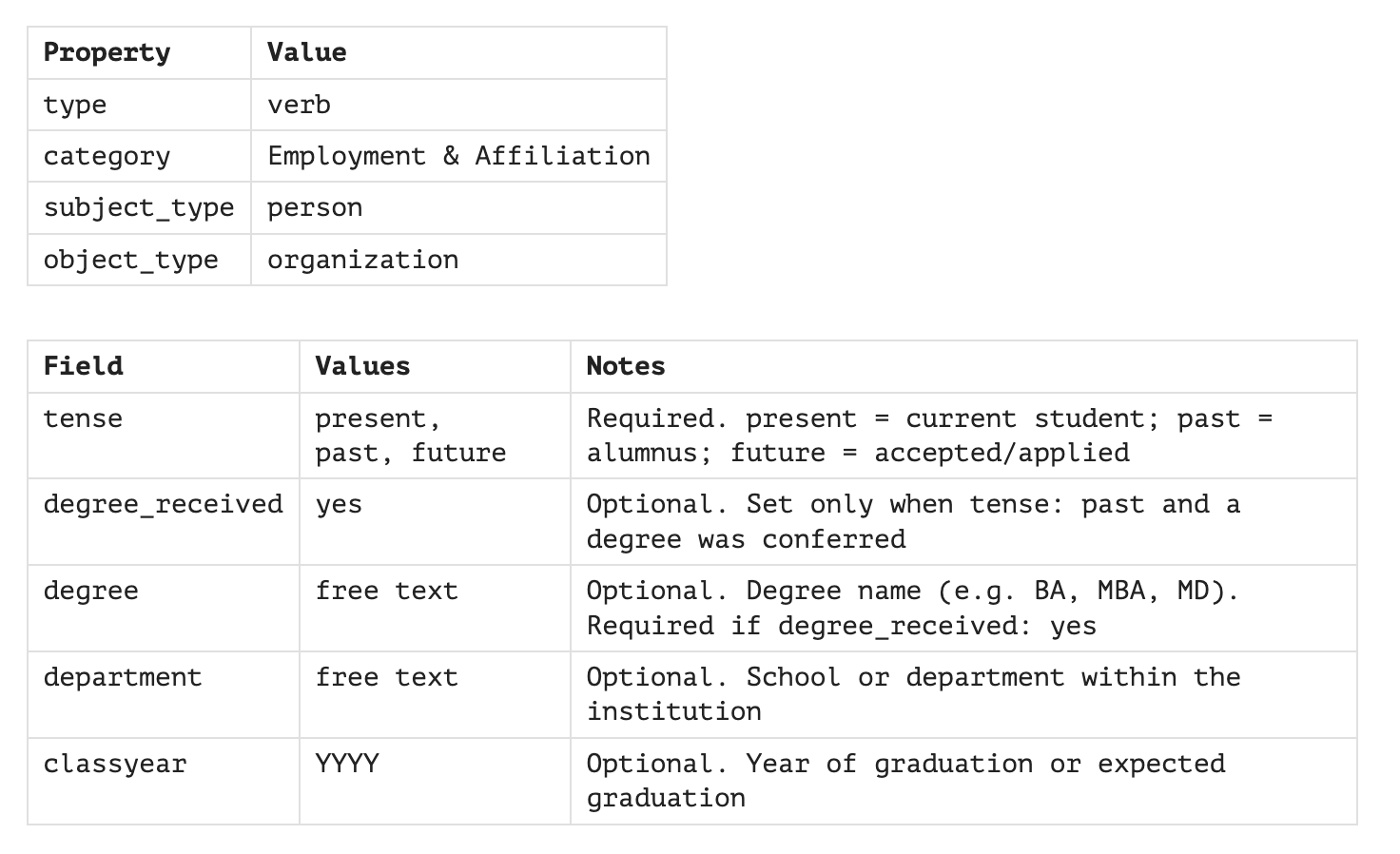
You see that any subject associated with “Attends” must be a person, and any object must be an organization. You also see that we can attach tense and degree information to the Attends verb. [8] We can separately track that:
Someone formerly attended Brown University and received an AB there
The same person currently might attend the Wharton School to receive an MBA there in 2026
Rules stored as data provide further validation. One rule mandates that degree_received cannot be yes if tense is present or future. Once you received the degree, you no longer attend the school (for that degree). [9]
Verbs are great, but how to store the connection between subjects, verbs and objects? We’ve also created millions of junction files over the years to link tables in a relational database. Why couldn’t I create a markdown junction template that linked nouns to verbs? For example, there is a junction file with the following information:

All of this is part of a Git repo with the version control and time-stamping that implies. I have nearly 5,000 junction files already—but that’s okay as each one tends to be about 300 bytes and I interrogate them programmatically rather than by hand. What’s the right way to do that?
Use agents for validation and queries
Even a couple of years ago this construct would have been impossible. What language would I have used to query the bloody thing? I would have had to write my own.
Claude Code skills create dashboards. Every morning at 3 am skills rip through the entire vault and create an updated dashboard for each person, project, organization, event and group. For example, for each project it interrogates the junction files to indicate
all the people participating in the project, with role
other projects where there is a dependency
milestones or outputs and status
meetings
documents
tasks
For ad-hoc queries, I tend to use the Cursor agent window. Each agent reads the relevant context on a part of the vault before interacting with me. For example Serena always has current context on TLF. Aaron, our agentic board secretary, always consumes current context on Brown-RISD Hillel.
A Python validator script runs on each commit. It checks verb schema conformance (subject/object types), field value constraints (rules), conditional field requirements, cardinality, symmetry, anti-reflexivity and prerequisite junctions. Yes, that’s deterministic, but agents help me write the script.
As a note, getting the verbs and the relationships between nouns and verbs required careful thought. I experienced massive verb sprawl—at one point close to 150 verbs—before I started using adverbs and tenses to get that down to a manageable number. I also had some wonderful linguistic discussions with Claude Code about, for example, the distinction between “Relates-to” and “Covers.”
This may be new and apply to a lot more than my personal knowledge base
Originally I had assumed I would grow my repository out of Obsidian and into a grown-up graph database environment. Data scientists and engineers who have worked with graph databases for years tell me this pattern—treating each relationship as a first-class file with its own typed schema—doesn’t have a clean analog in the systems they’ve used.
That’s interesting because the same ambiguity that applies in my life also applies to many big, complicated, messy corporate functions—large change programs, regulatory compliance, B2B sales. The same pattern for managing relationships across ambiguous data sets might apply in these domains, creating new opportunities for insight analytics and agentic automation.
A bank running a consent order has hundreds of requirements, each with a control, each control backed by evidence, each piece of evidence tied to a document, each document owned by a workstream, each workstream staffed by people with specific roles. In most implementations, that information lives in a spreadsheet or a SharePoint folder tree—which means someone manually checks that every requirement has a control, every control has evidence, and every piece of evidence points to a real document. That someone is usually a program manager doing it with Ctrl+F.
The approach used in ProsaicGraff would make those connections typed and validated. The link between a control and its evidence isn’t a cell reference—it’s a relationship with a schema that says: this field is required, this value must come from this list, and if this condition is true, this other field must be populated.
The validator runs on every commit and tells you exactly which requirements are missing controls, which controls have no evidence, and which documents are referenced but don’t exist. The audit trail is Git history. You don’t need a program manager with a spreadsheet. You need a commit hook.
In a labeled property graph the control-to-evidence edge exists, but it’s a set of key-value pairs—you can put whatever keys you want on it, or none at all. Nothing in the database enforces that every control–evidence edge has an evidence_type field, or that evidence_type is one of {documented, tested, attested}, or that if status is closed then closure_date must be populated. You write that logic in application code, or in a separate validation layer, or you rely on the program team to do it manually.
When the compliance team provides new guidance on what “adequate evidence” means—you update the application code, retest it, redeploy it, and hope the existing edges that now violate the new rule get caught before the examiner does.
In RDF you get the semantic precision but at significant operational cost. SHACL can express exactly these constraints, but it runs as an external reasoning layer—it’s not native to the store. The triples themselves are clean but verbose; every relationship requires multiple statements to capture what a single ProsaicGraff junction file captures.
In ProsaicGraff the constraint is a file. Changing what “adequate evidence” means is a one-line edit to a rule file, committed to Git, with a timestamp and an author. The validator immediately surfaces every edge that violates the new rule. The audit trail of the constraint change is as durable as the audit trail of the data.
Here are a few domains where this approach might be interesting.
Enterprise sales — Full provenance of relationships: who introduced whom, when, through what channel; multi-employer, multi-institution history; temporal tracking via tense
Corporate program management — Program structure as a graph; sponsor, workstreams, vendors, dependencies—all typed and property-bearing; roles distinguished without schema changes
Regulatory compliance documentation — Traceable requirement → control → evidence chains; each control can cover a specific requirement with a typed relationship; conditional fields enforce documentation completeness
M&A / due diligence — Ownership trees, management networks, and findings as a unified graph; conflicting findings formally modeled via contradiction
Investment thesis management — Full argumentation graph: thesis → supporting propositions → facts → sources; counter-evidence modeled; confidence tracked
RFP and proposal management — Who worked on what for whom, in what role, producing which deliverables; knowledge reuse across proposals
There is much baseball left to play here
Obviously, this is an experiment, not a platform. I have 5,000 junctions running on my laptop. Applying the pattern to an enterprise-grade domain touching hundreds (if not thousands) of users would imply millions of junctions per installation. Some colleagues and I have talked about how we might extend it.
For example, we might store transactions rather than state. Right now we store state: Kaplan-James is employed by McKinsey. Would it increase analytic power if we stored transactions (McKinsey hired Kaplan-James) and derived state? If we did that, would we need a defined starting state? That shift would do wonders for temporal queries.
We could also use SQLite to create a more performant query layer. We could add a lightweight inference layer—maybe that naturally follows if we move from storing state to storing transactions?
I want to put some real thought into extending the argumentation model and creating a robust framework for decomposing goals into actions and into tasks.
Footnotes
[1] In some cases, colleagues think I’m a Chaos Muppet because, as a disciple of Edward Tufte, I insist on understanding complexity and refuse to paper over it with over-synthesis. Shortly after I met my colleague Brian Elliott he told me “I will go to any level of granularity I need to in order to solve the problem.” And I thought: “We are so going to be pals.”
[2] Because we’re doing Muppet discourse, I might as well share one of my Dad’s favorite stories. The Muppet Show launched in fall 1976—I was six. My mom had a PTA meeting, or something that evening, so Dad, Rob and I settled in to watch this new show.
There was a running gag in which the old-fashioned phone backstage would ring. And when someone picked it up? Chaos! Not a voice on the line, but coins or water streaming out of the speaker. I found it hilarious.
As you might imagine I was an unusually articulate six-year-old, the kind who believed that if you explained your point clearly even an adult might understand. But when my mom returned, my glibness failed me. I could not get the words out quickly enough to explain how exciting and funny the show had been.
Like me, my dad likes to recount stories, so I don’t know how many hundreds of times I’ve heard his impression of me trying to get the words out to explain the telephone to my mother. In part, I suspect he figures he should treasure one of the few times he saw his older son at a loss for words.
[3] Frequently heard around the Prosaic Times newsroom, at least when Matthew is home from college—
Matthew: I need a charging cable for my iPhone
Daddy: [Looks up from book. Says nothing. Raises eyebrows.]
Matthew: You mean I should go in the utility, look for the clear plastic bin that says “USB-C to USB-C cables” and get one from there.
Daddy: That sounds like a plausible hypothesis about the world, grounded in past experience. You should test it.
Matthew: Other kids have normal dads.
Daddy: You would get bored.
[4] Except for the factories. If Sam the Eagle is on the executive committee, he’s the SVP, Operations.
[5] As an Order Muppet, I crave structure. That doesn’t mean I love process. In fact I hate it.
[6] Oh, yes, I learned a lot playing with Obsidian and Cursor.
I made every mistake possible in setting up my Obsidian vault. Don’t take any of this as a criticism of Obsidian, which I love—all of these organizing constructs appear in multiple contexts and always have the same limitations.
Sub-folders are inflexible. We’ve all used folders and sub-folders in our file systems to organize documents. It rarely works because a folder tree is hierarchical and life isn’t. Also folders don’t have metadata beyond the folder name. None of this works any better in Obsidian than it does in File Explorer or Finder.
Hashtags don’t scale. Yes, hashtags are flexible. Yes, hashtag hierarchies are sort of cool, but they quickly become unworkable at any sort of scale. Syntax enforcement? Hardly. And any individual hashtag is a thin channel for information. The hashtag #StandardSocks tells us a note has something to do with that company, but not what.
Links are semantically shallow. You can create wiki-style links easily in Obsidian. Just type StandardSocks and a click will take you there. Great for navigation, less so for analysis. Yes, this statement relates to that document, but how?
Front matter gets messy. Obsidian’s support for YAML front matter is very powerful, but eventually runs into scale problems all its own. As you would expect, I have many different types of people in my Obsidian vault—McKinsey colleagues, clients, people in the Brown University ecosystem—each of which requires slightly different combinations of metadata. Eventually you either wind up with dozens of sparsely populated front-matter fields or you start segmenting your templates, which creates other problems.
All of this creates a combinatorial meta-problem. Each organizing construct works better for different uses, but then you wind up asking yourself “wait, did I use front matter or wikilinks to connect people to projects?” Questions like these do not reduce psychic entropy.
Cursor helps, a little. The agent window reduces overhead in updating data and performing ad-hoc queries, but doesn’t reduce the underlying complexity.
[7] Jane Schnauggs is a composite for illustration. Interested in her adventures with the Senate Homeland Security and Governmental Affairs Committee when HyperCare, Inc. suffered a cyberattack while she was CIO there? See Chapter 2 of Beyond Cybersecurity: Protecting Your Digital Business.
[8] When I get a chance I will probably create a taxonomy of majors (e.g. history, English, etc.) and degrees (AB, ScB, MBA, JD, etc.) and make those fields non–free-text. That will make analytics a bit easier here.
[9] Schema rule: once a degree is awarded, you shouldn’t still mark that program as present- or future-tense “attends” for that credential.
Great piece - some brilliant exploration that you're doing here James.
One of the things I'm most curious about is the 33 verbs - how you picked those and how satisfied you are with the coverage / simplicity trade-off! (Why not more? Why not fewer?)
I'm doing some similar work and exploration, and I often find it a tricky decision in something like: "Well, we could add _just one more_ relationship type for what we're modelling here, which captures a key nuance which isn't quite reflected in what we have available - but if we keep doing this, we'll end up with a sprawling ontology".
(Currently, my approach is to try to keep the structured relationship types relatively slim, but allow free text for an agent to add color / nuance; I'm not certain this is the right trade-off or best approach)